Approximate Computation on Big Data
ICDE (2), TKDE (1), WSDM (1)
[ICDE-2018] Query Independent Scholarly Article Ranking
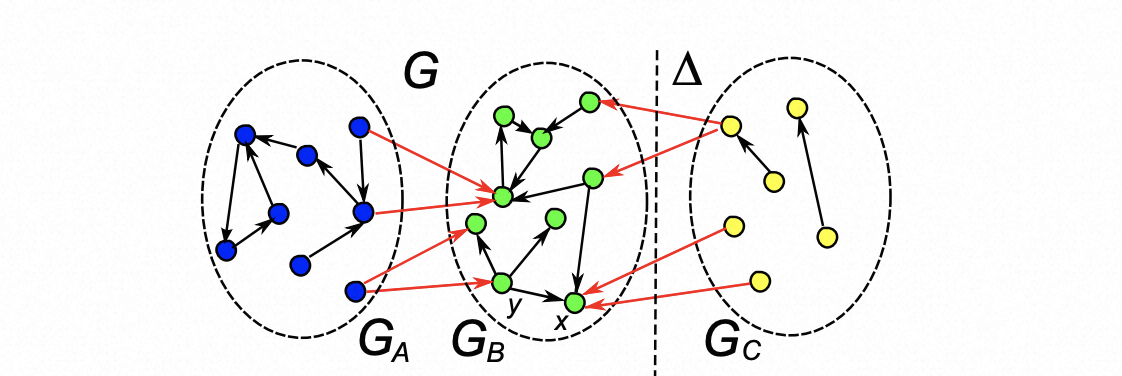
Ranking query independent scholarly articles is a practical and difficult task, due to the heterogeneous, evolving and dynamic nature of entities involved in scholarly articles. To do this, we first propose a scholarly article ranking model by assembling the importance of involved entities (i.e., articles, venues and authors) such that the importance is a combination of prestige and popularity to capture the evolving nature of entities. To compute the prestige of articles and venues, we propose a novel Time-Weighted PageRank that extends traditional PageRank with a time decaying factor. We then develop a batch algorithm for scholarly article ranking, in which we propose a block-wise method for Time-Weighted PageRank in terms of an analysis of the citation characteristics of scholarly articles. We further develop an incremental algorithm for dynamic scholarly article ranking, which partitions graphs into affected and unaffected areas, and employs different updating strategies for nodes in different areas. Using real-life data, we finally conduct an extensive experimental study, and show that our approach is both effective and efficient for ranking scholarly articles.
[ICDE-2017] Fast Computation of Dense Temporal Subgraphs
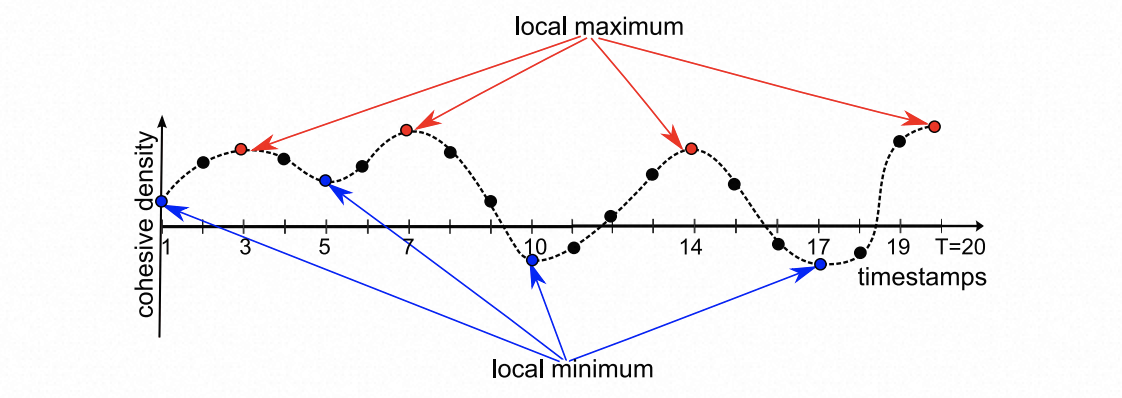
Dense subgraph discovery has proven useful in various applications of temporal networks. We focus on a special class of temporal networks whose nodes and edges are kept fixed, but edge weights constantly and regularly vary with timestamps. However, finding dense subgraphs in temporal networks is nontrivial, and its state of the art solution uses a filter-and-verification framework, which is not scalable on large temporal networks. In this study, we propose a data-driven approach to finding dense subgraphs in large temporal networks with T timestamps. (1) We first develop a data-driven approach employing hidden statistics to identifying k time intervals, instead of T ∗ (T + 1)/2 ones (k is typically much smaller than T ), which strikes a balance between quality and efficiency. (2) After proving that the problem has no constant factor approximation algorithms, we design better heuristic algorithms to attack the problem, by building the connection of finding dense subgraphs with a variant of the Prize Collecting Steiner Tree problem. (3) Finally, we have conducted an extensive experimental study to demonstrate the effectiveness and efficiency of our approach, using real-life and synthetic data.