Robust and Explainable Machine Learning
AAAI (1), IJCAI (2), WSDM (1)
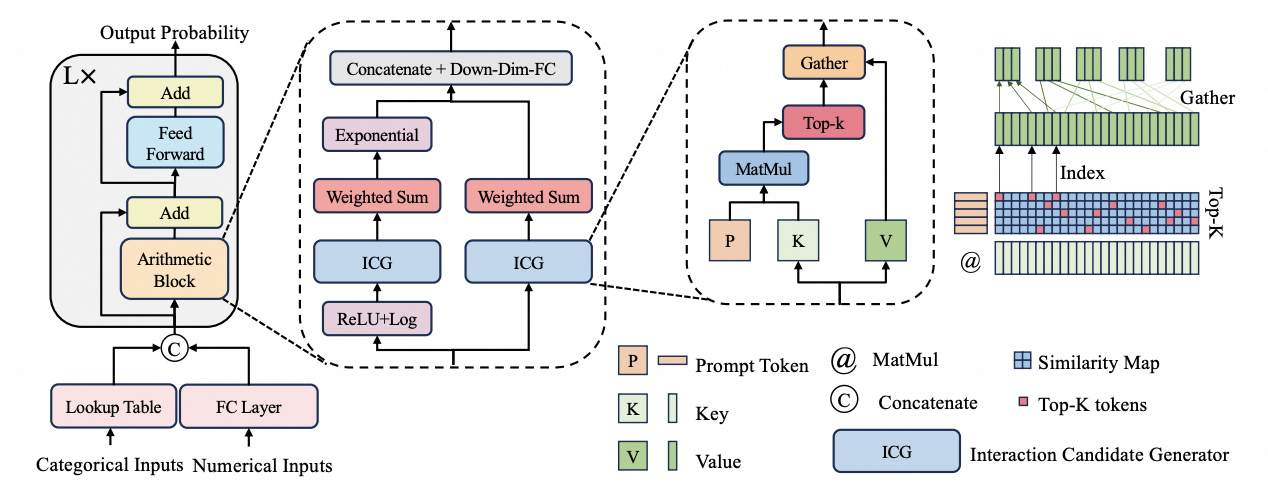
[AAAI-2024] Robust Image Ordinal Regression with Controllable Image Generation
Until recently, the question of the effective inductive bias of deep models on tabular data has remained unanswered. This paper investigates the hypothesis that arithmetic feature interaction is necessary for deep tabular learning. To test this point, we create a synthetic tabular dataset with a mild feature interaction assumption and examine a modified transformer architecture enabling arithmetical feature interactions, referred to as AMFormer. Results show that AMFormer outperforms strong counterparts in fine-grained tabular data modeling, data efficiency in training, and generalization. This is attributed to its parallel additive and multiplicative attention operators and prompt-based optimization, which facilitate the separation of tabular samples in an extended space with arithmetically-engineered features. Our extensive experiments on real-world data also validate the consistent effectiveness, efficiency, and rationale of AMFormer, suggesting it has established a strong inductive bias for deep learning on tabular data.
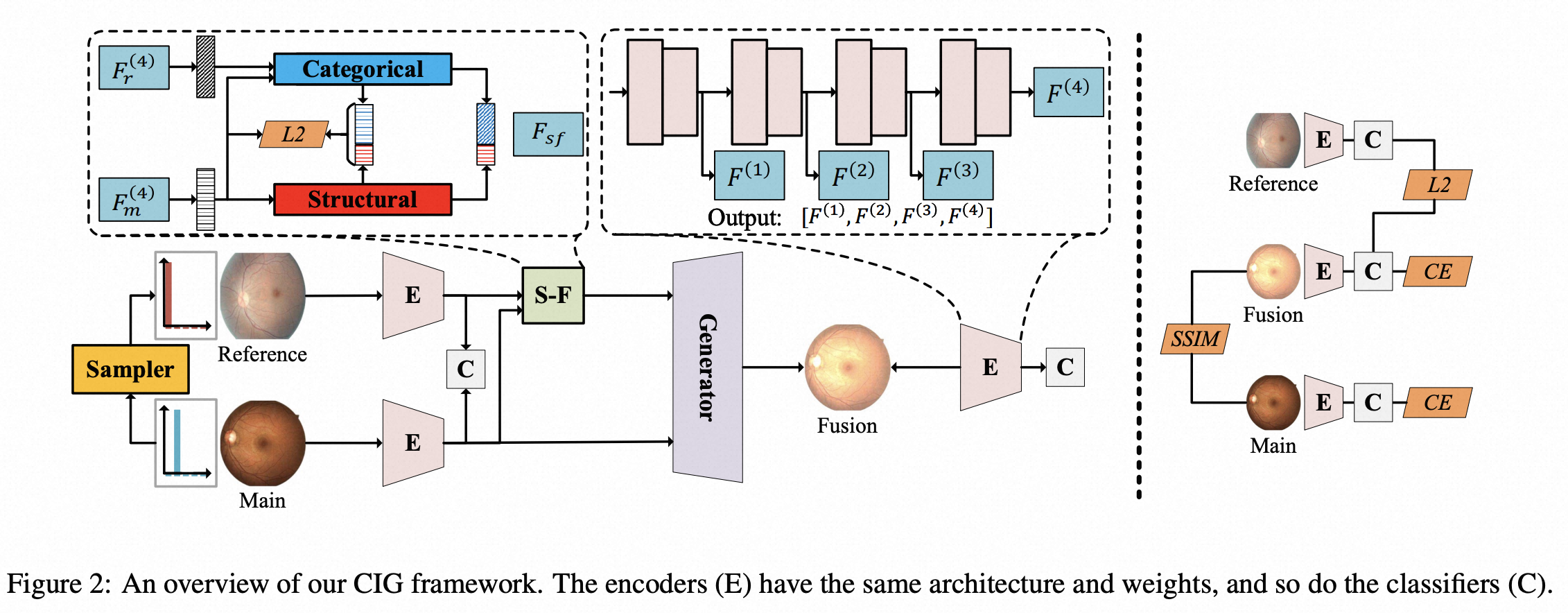
[IJCAI-2023] Robust Image Ordinal Regression with Controllable Image Generation
Image ordinal regression has been mainly studied along the line of exploiting the order of categories. However, the issues of class imbalance and category overlap that are very common in ordinal regression were largely overlooked. As a result, the performance on minority categories is often unsatisfactory. In this paper, we propose a novel framework called CIG based on controllable image generation to directly tackle these two issues. Our main idea is to generate extra training samples with specific labels near category boundaries, and the sample generation is biased toward the less-represented categories. To achieve controllable image generation, we seek to separate structural and categorical information of images based on structural similarity, categorical similarity, and reconstruction constraints. We evaluate the effectiveness of our new CIG approach in three different image ordinal regression scenarios. The results demonstrate that CIG can be flexibly integrated with off-the-shelf image encoders or ordinal regression models to achieve improvement, and further, the improvement is more significant for minority categories.
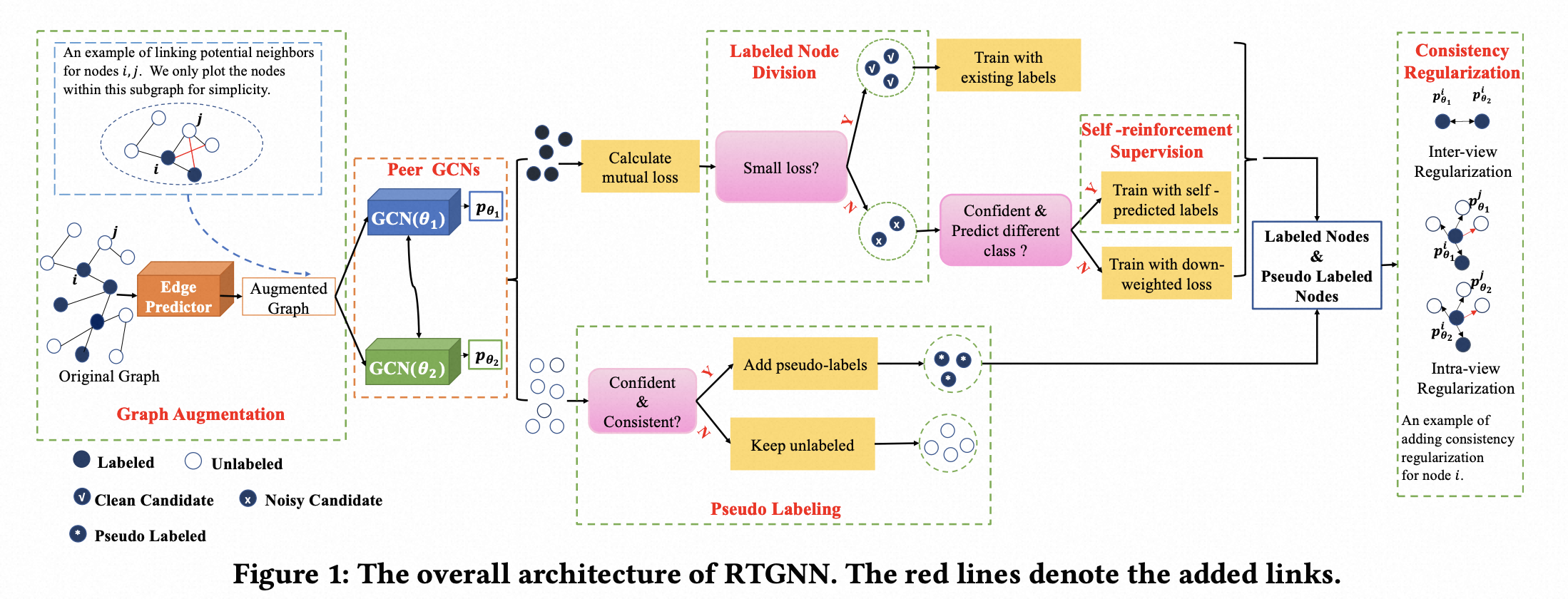
[WSDM-2023] Robust Training of Graph Neural Networks via Noise Governance
Graph Neural Networks (GNNs) have become widely-used models for semi-supervised learning. However, the robustness of GNNs in the presence of label noise remains a largely under-explored problem. In this paper, we consider an important yet challenging scenario where labels on nodes of graphs are not only noisy but also scarce. In this scenario, the performance of GNNs is prone to degrade due to label noise propagation and insufficient learning. To address these issues, we propose a novel RTGNN (Robust Training of Graph Neural Networks via Noise Governance) framework that achieves better robustness by learning to explicitly govern label noise. More specifically, we introduce self-reinforcement and consistency regularization as supplemental supervision. The self-reinforcement supervision is inspired by the memorization effects of deep neural networks and aims to correct noisy labels. Further, the consistency regularization prevents GNNs from overfitting to noisy labels via mimicry loss in both the inter-view and intra-view perspectives. To leverage such supervisions, we divide labels into clean and noisy types, rectify inaccurate labels, and further generate pseudo-labels on unlabeled nodes. Supervision for nodes with different types of labels is then chosen adaptively. This enables sufficient learning from clean labels while limiting the impact of noisy ones. We conduct extensive experiments to evaluate the effectiveness of our RTGNN framework, and the results validate its consistent superior performance over state-of-the-art methods with two types of label noises and various noise rates.
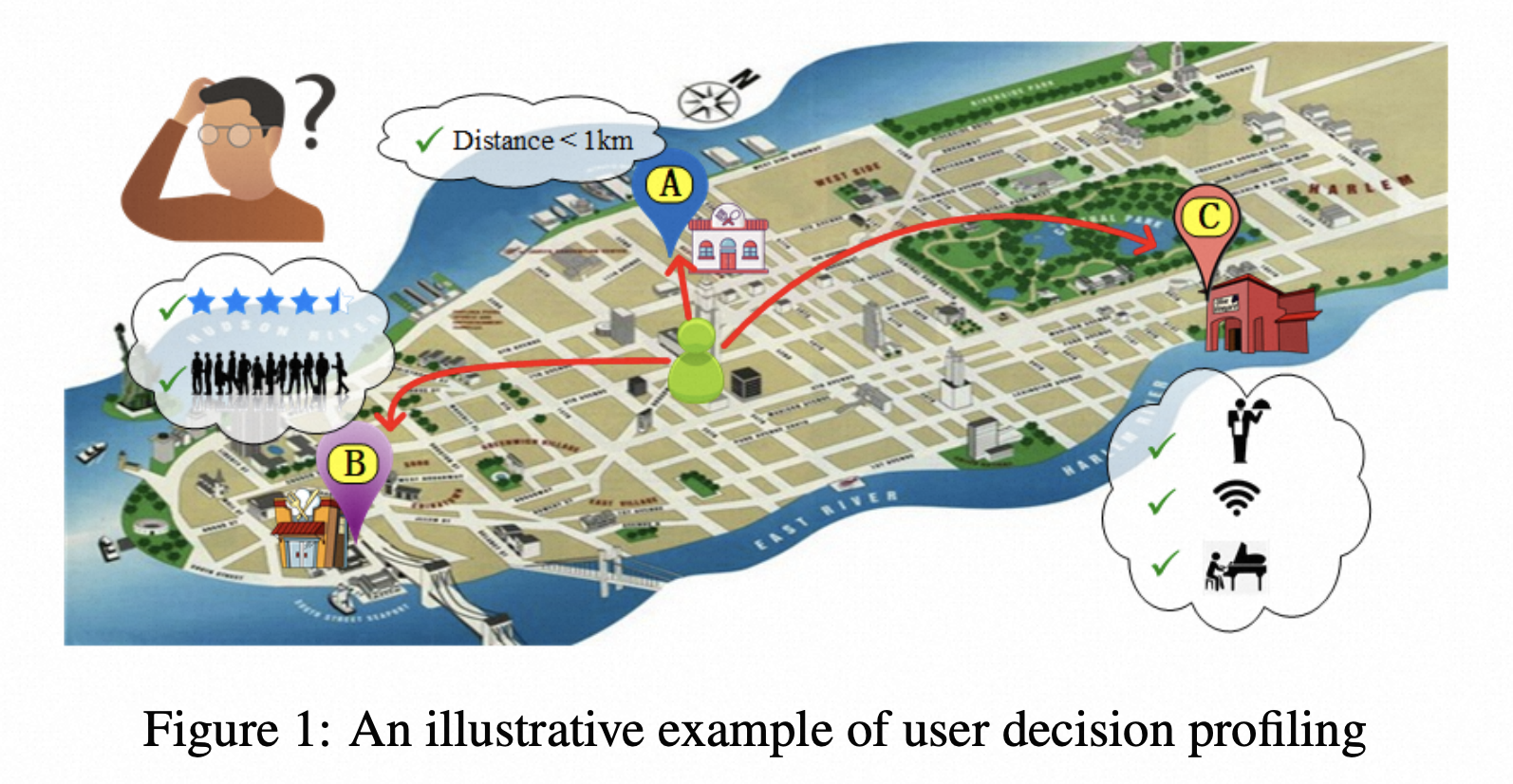
[IJCAI-2020] Why We Go Where We Go: Profiling User Decisions on Choosing POIs
While Point-of-Interest (POI) recommendation has been a popular topic of study for some time, little progress has been made for understanding why and how people make their decisions for the selection of POIs. To this end, in this paper, we propose a user decision profiling framework, named PROUD, which can identify the key factors in people's decisions on choosing POIs. Specifically, we treat each user decision as a set of factors and provide a method for learning factor embeddings. A unique perspective of our approach is to identify key factors, while preserving decision structures seamlessly, via a novel scalar projection maximization objective. Exactly solving the objective is non-trivial due to a sparsity constraint. To address this, our PROUD adopts a self projection attention and an L2 regularized sparse activation to directly estimate the likelihood of each factor to be a key factor. Finally, extensive experiments on real-world data validate the advantage of PROUD in preserving user decision structures. Also, our case study indicates that the identified key decision factors can help us to provide more interpretable recommendations and analyses.